Label Studio Documentation
Discover how to build custom UIs or take advantage of pre-built labeling templates, manage team member permissions and workflows, and much more.
Cloud Setup Guide On-Prem Installation Guide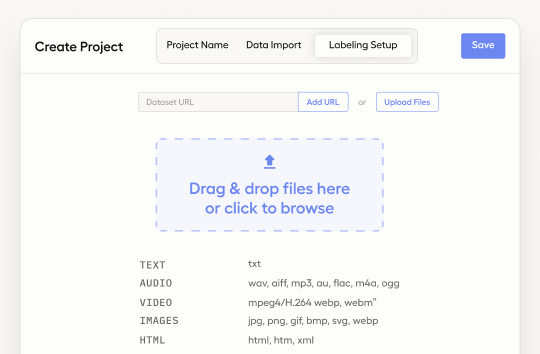
Label Studio 101
Brand new to Label Studio? We've created a jam-packed new tutorial with the most important information to get you up and running.
Get started
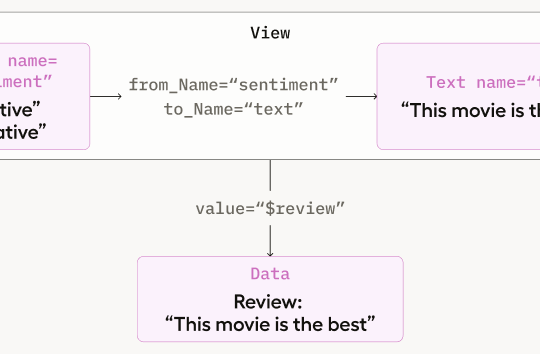
Machine Learning with Label Studio
Learn the background knowledge and steps required to integrate Machine Learning models into your Label Studio workflow.
Learn more
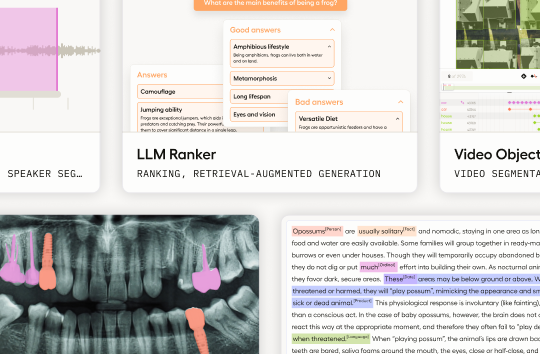
Use templates
Label Studio provides multiple out-of-the-box labeling configurations to help get you started.
Explore templates