Draft and run prompts
With your Prompt created, you can begin drafting your prompt content to run against baseline tasks.
Draft a prompt and generate predictions
Select your base model.
The models that appear depend on the API keys that you have configured for your organization.
In the Prompt field, enter your prompt. Keep in mind the following:
- You must include the text variables. These appear directly above the prompt field. (In the demo below, this is the
reviewvariable.) Click the text variable name to insert it into the prompt. - Although not strictly required, you should provide definitions for each class to ensure prediction accuracy and to help add context.
- You must include the text variables. These appear directly above the prompt field. (In the demo below, this is the
Tip
You can generate an initial draft by simply adding the text variables and then clicking Enhance Prompt.
Select your baseline:
All Project Tasks - Generate predictions for all tasks in the project. Depending on the size of your project, this might take some time to process. This does not generate an accuracy score for the prompt.
See the Bootstrapping projects with prompts use case.
Sample Tasks - Generate predictions for the first 20 tasks in the project. This does not generate an accuracy score for the prompt.
See the Bootstrapping projects with prompts use case.
Ground Truths - Generate predictions and a prompt accuracy score for all tasks with ground truth annotations. This option is only available if your project has ground truth annotations.
See the Auto-labeling with Prompts use case and the Prompt evaluation and fine-tuning.
If this is your first version of the prompt or you want to adjust the current version, click Save.
If you want to create a new version of the prompt so that you can compare evaluations between versions, click the drop-down menu next to Save and select Save As.
Click Evaluate (if running against a ground truth baseline) or Run.
warning
When you click Evaluate or Run, you will create predictions for each task in the baseline you selected and overwrite any previous predictions you generated with this prompt.
Evaluating your Prompts can result in multiple predictions on your tasks: if you have multiple Prompts for one Project, or if you click both Evaluate/Run and Get Predictions for All Tasks from a Prompt, you will see multiple predictions for tasks in the Data Manager.
Evaluation results
When you evaluate a prompt, you will see the following metrics:
| Metric | Tasks | Config | Description |
|---|---|---|---|
|
Overall accuracy |
Ground Truths |
All labeling configs |
A measure of how many predictions are correct when measured against the ground truth. For example, if there are 10 ground truths and your Prompt’s predictions match 7 of them, then the overall accuracy would be |
|
Outputs |
All task types |
All labeling configs |
Number of tasks evaluated. |
|
F1 Score |
Ground Truths |
Single Single |
The F1 score is a metric to assess a machine learning model’s accuracy. This is measured in terms of precision and recall as follows:
Note that a “positive” prediction denotes either a ‘positive’ label (like a checkbox), or the presence of a particular choice/label in the prediction. |
|
Inference cost |
All task types |
All labeling configs |
The cost to run the prompt based on the number of tokens required. |
Classification reports
Click Expand to view classification reports for the Prompt. Thee reports tell you how many times each class was identified. This is available for the following tags:
ChoicesLabelsPairwiseRating
Enhance prompt
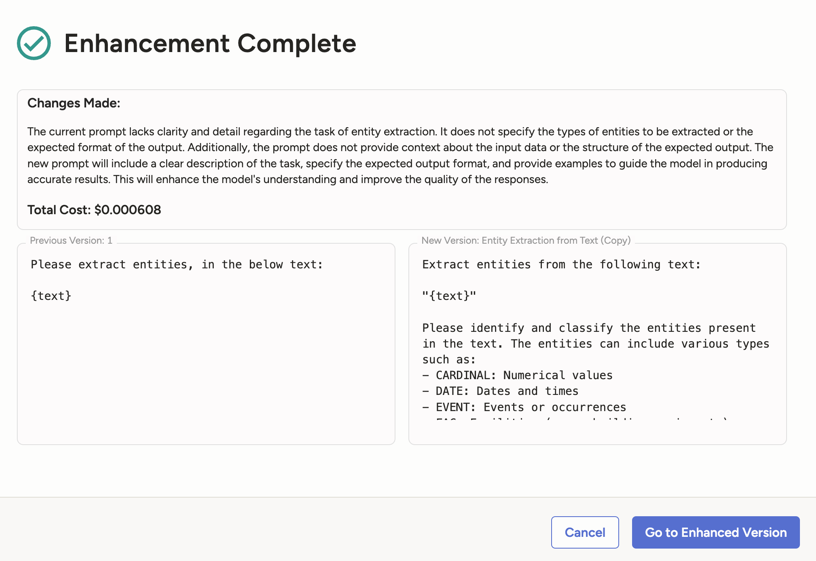
You can use Enhance Prompt to help you construct and auto-refine your prompts.
At minimum, you need to insert the text variable first. (Click the text variable name to insert it into the prompt. These appear above the prompts field).
From the Enhance Prompt window you will need to select the Teacher Model that you want to use to write your prompt. As you auto-refine your prompt, you’ll get the following:
- A new prompt displayed next to the previous prompt.
- An explanation of the changes made.
- The estimated cost spent auto-refining your prompt.
How it works
The Task Subset is used as the context when auto-refining the prompt. If you have ground truth data available, that will serve as the task subset. Otherwise, a sample of up to to 10 project tasks are used.
Auto-refinement applies your initial prompt and the Teacher Model to generate predictions on the task subset (which will be ground truth tasks or a sample dataset). If applicable, predictions are then compared to the ground truth for accuracy.
Your Teacher Model evaluates the initial prompt’s predictions against the ground truth (or sample task output) and identifies areas for improvement. It then suggests a refined prompt, aimed at achieving closer alignment with the desired outcomes.
Drafting effective prompts
For a comprehensive guide to drafting prompts, see The Prompt Report: A Systematic Survey of Prompting Techniques or OpenAI’s guide to Prompt Engineering.
Text placement
When you place your text variable in the prompt (review in the demo above), this placeholder will be replaced by the actual text.
Depending on the length and complexity of your text, inserting it into the middle of another sentence or thought could potentially confuse the LLM.
For example, instead of “Classify text as one of the following:“, try to structure it as something like, “Given the following text: text. Classify this text as one of the following:.”
Define your objective
The first step to composing an effective prompt is to clearly define the task you want to accomplish. Your prompt should explicitly state that the goal is to classify the given text into predefined categories. This sets clear expectations for the model. For instance, instead of a vague request like “Analyze this text,” you should say, “Classify the following text into categories such as ‘spam’ or ‘not spam’.” Clarity helps the model understand the exact task and reduces ambiguity in the responses.
Add context
Context is crucial in guiding the model towards accurate classification. Providing background information or examples can significantly enhance the effectiveness of the prompt. For example, if you are classifying customer reviews, include a brief description of what constitutes a positive, negative, or neutral review. You could frame it as, “Classify the following customer review as ‘positive,’ ‘negative,’ or ‘neutral.’ A positive review indicates customer satisfaction, a negative review indicates dissatisfaction, and a neutral review is neither overly positive nor negative.” This additional context helps the model align its responses with your specific requirements.
Specificity
Specificity in your prompt enhances the precision of the model’s output. This includes specifying the format you want for the response, any particular keywords or phrases that are important, and any other relevant details. For instance, “Please classify the following text and provide the category in a single word: ‘positive,’ ‘negative,’ or ‘neutral.’” By being specific, you help ensure that the model’s output is consistent and aligned with your expectations.