Prompts examples
Example project types
Text classification
Text classification is the process of assigning predefined categories or labels to segments of text based on their content. This involves analyzing the text and determining which category or label best describes its subject, sentiment, or purpose. The goal is to organize and categorize textual data in a way that makes it easier to analyze, search, and utilize.
Text classification labeling tasks are fundamental in many applications, enabling efficient data organization, improving searchability, and providing valuable insights through data analysis. Some examples include:
- Spam Detection: Classifying emails as “spam” or “ham” (not spam).
- Sentiment Analysis: Categorizing user reviews as “positive,” “negative,” or “neutral.”
- Topic Categorization: Assigning articles to categories like “politics,” “sports,” “technology,” etc.
- Support Ticket Classification: Labeling customer support tickets based on the issue type, such as “billing,” “technical support,” or “account management.”
- Content Moderation: Identifying and labeling inappropriate content on social media platforms, such as “offensive language,” “hate speech,” or “harassment.”
Named entity recognition (NER)
A Named Entity Recognition (NER) labeling task involves identifying and classifying named entities within text. For example, people, organizations, locations, dates, and other proper nouns. The goal is to label these entities with predefined categories that make the text easier to analyze and understand. NER is commonly used in tasks like information extraction, text summarization, and content classification.
For example, in the sentence “Heidi Opossum goes grocery shopping at Aldi in Miami” the NER task would involve identifying “Aldi” as a place or organization, “Heidi Opossum” as a person (even though, to be precise, she is an iconic opossum), and “Miami” as a location. Once labeled, this structured data can be used for various purposes such as improving search functionality, organizing information, or training machine learning models for more complex natural language processing tasks.
NER labeling is crucial for industries such as finance, healthcare, and legal services, where accurate entity identification helps in extracting key information from large amounts of text, improving decision-making, and automating workflows.
Some examples include:
- News and Media Monitoring: Media organizations use NER to automatically tag and categorize entities such as people, organizations, and locations in news articles. This helps in organizing news content, enabling efficient search and retrieval, and generating summaries or reports.
- Intelligence and Risk Analysis: By extracting entities such as personal names, organizations, IP addresses, and financial transactions from suspicious activity reports or communications, organizations can better assess risks and detect fraud or criminal activity.
- Specialized Document Review: Once trained, NER can help extract industry-specific key entities for better document review, searching, and classification.
- Customer Feedback and Product Review: Extract named entities like product names, companies, or services from customer feedback or reviews. This allows businesses to categorize and analyze feedback based on specific products, people, or regions, helping them make data-driven improvements.
Text summarization
Text summarization involves condensing large amounts of information into concise, meaningful summaries.
Models can be trained or fine-tuned to recognize essential information within a document and generate summaries that retain the core ideas while omitting less critical details. This capability is especially valuable in today’s information-heavy landscape, where professionals across various fields are often overwhelmed by the sheer volume of text data.
Some examples include:
- Customer Support and Feedback Analysis: Companies receive vast volumes of customer support tickets, reviews, and feedback that are often repetitive or lengthy. Auto-labeling can help summarize these inputs, focusing on core issues or themes, such as “billing issues” or “technical support.”
- News Aggregation and Media Monitoring: News organizations and media monitoring platforms need to process and distribute news stories efficiently. Auto-labeling can summarize articles while tagging them with labels like “politics,” “economy,” or “health,” making it easier for users to find relevant stories.
- Document Summarization: Professionals often need to quickly understand the key points in lengthy contracts, research papers, and files.
- Educational Content Summarization: EEducators and e-learning platforms need to distill complex material into accessible summaries for students. Auto-labeling can summarize key topics and categorize them under labels like “concept,” “example,” or “important fact.”
Image captioning and classification
Image captioning involves applying descriptive text for images. This has valuable applications across industries, particularly where visual content needs to be systematically organized, analyzed, or made accessible.
You can also use Prompts to automatically categorizing images into predefined classes or categories, ensuring consistent labeling of large image datasets.
Some examples include:
E-commerce Product Cataloging: Online retailers often deal with thousands of product images that require captions describing their appearance, features, or categories.
Digital Asset Management (DAM): Companies managing large libraries of images, such as marketing teams, media organizations, or creative agencies, can use auto-labeling to caption, tag, and classify their assets.
Content Moderation and Analysis: Platforms that host user-generated content can employ image captioning to analyze and describe uploaded visuals. This helps detect inappropriate content, categorize posts (e.g., “Outdoor landscape with a sunset”), and surface relevant content to users. You may also want to train a model to classify image uploads into categories such as “safe,” “explicit,” or “spam.”
Accessibility for Visually Impaired Users: Image captioning is essential for making digital content more accessible to visually impaired users by providing descriptive alt-text for images on websites, apps, or documents. For instance, an image of a cat playing with yarn might generate the caption, “A fluffy orange cat playing with a ball of blue yarn.”
Tip
You can use the valueList parameter to include a series of images within each task. See this template for an example of valueList in use.
Example Walkthroughs
Autolabel image captions
This example demonstrates how to set up Prompts to predict image captions.
Create a new label studio project by importing image data via cloud storage.
If you’d like to, you can generate a dataset to test the process using https://data.heartex.net.
note
Prompts does not currently support image data uploaded as raw images. Only image references (HTTP URIs to images) or images imported via cloud storage are supported.
- Create a label config for image captioning (or Ask AI to create one for you), for example:
<View>
<Image name="image" value="$image"/>
<Header value="Describe the image:"/>
<TextArea name="caption" toName="image" placeholder="Enter description here..."
rows="5" maxSubmissions="1"/>
</View>Navigate to Prompts from the sidebar, and create a prompt for the project
If you have not yet set up API the keys you want to use, do that now: API keys.
Add the instruction you’d like to provide the LLM to caption your images. For example:
Explain the contents of the following image:
{image}
note
Ensure you include {image} in your instructions. Click image above the instruction field to insert it.
Tip
You can also automatically generate the instructions using the Enhance Prompt action. Before you can use this action, you must at least add the variable name {image} and then click Save.
Run the prompt! View predictions to accept or correct.
You can read more about evaluation metrics and ways to assess your prompt performance.
Tip
You can change the subset of data being used (e.g. only data with Ground Truth annotations, or a small sample of records).
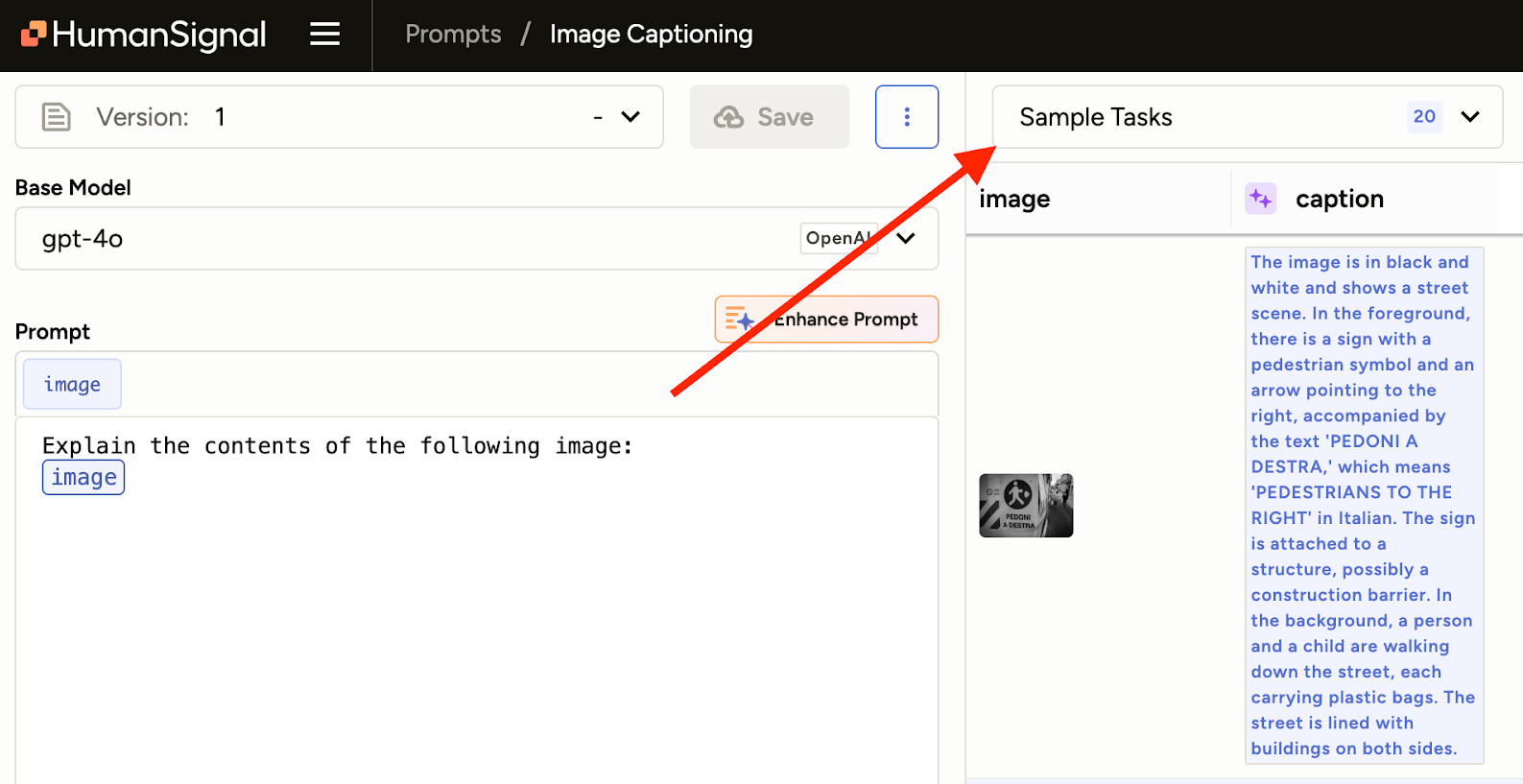
- Accept the predictions as annotations!
Evaluate LLM outputs for toxicity
This example demonstrates how to set up Prompts to evaluate if the LLM-generated output text is classified as harmful, offensive, or inappropriate.
Create a new label studio project by importing text data of LLM-generated outputs.
For example: you can use the jigsaw_toxicity dataset as an example. See the appendix for how you can pre-process and (optionally) downsample this dataset to use with this guide.
Create a label config for toxicity detection (or Ask AI to create one for you), for example:
<View>
<Header value="Comment" />
<Text name="comment" value="$comment_text"/>
<Header value="Toxic" size="3"/>
<Choices name="toxic" toName="comment" choice="single" showInline="true">
<Choice value="Yes" alias="1"/>
<Choice value="No" alias="0"/>
</Choices>
<Header value="Severely Toxic" size="3"/>
<Choices name="severe_toxic" toName="comment" choice="single" showInline="true">
<Choice value="Yes" alias="1"/>
<Choice value="No" alias="0"/>
</Choices>
<Header value="Insult" size="3"/>
<Choices name="insult" toName="comment" choice="single" showInline="true">
<Choice value="Yes" alias="1"/>
<Choice value="No" alias="0"/>
</Choices>
<Header value="Threat" size="3"/>
<Choices name="threat" toName="comment" choice="single" showInline="true">
<Choice value="Yes" alias="1"/>
<Choice value="No" alias="0"/>
</Choices>
<Header value="Obscene" size="3"/>
<Choices name="obscene" toName="comment" choice="single" showInline="true">
<Choice value="Yes" alias="1"/>
<Choice value="No" alias="0"/>
</Choices>
<Header value="Identity Hate" size="3"/>
<Choices name="identity_hate" toName="comment" choice="single" showInline="true">
<Choice value="Yes" alias="1"/>
<Choice value="No" alias="0"/>
</Choices>
<Header value="Reasoning" size="3"/>
<TextArea name="reasoning" toName="comment" editable="true" placeholder="Provide reasoning for your choices here..."/>
</View>Navigate to Prompts from the sidebar, and create a prompt for the project
If you have not yet set up API the keys you want to use, do that now: API keys.
Add the instruction you’d like to provide the LLM to best evaluate the text. For example:
Determine whether the following text falls into any of the following categories (for each, provide a “0” for False and “1” for True):
toxic, severe_toxic, insult, threat, obscene, and identity_hate.
Comment:
{comment_text}
note
Ensure you include {comment_text} in your instructions. Click comment_text above the instruction field to insert it.
Tip
You can also automatically generate the instructions using the Enhance Prompt action. Before you can use this action, you must at least add the variable name {comment_text} and then click Save.
Run the prompt! View predictions to accept or correct.
You can read more about evaluation metrics and ways to assess your prompt performance.
Tip
You can change the subset of data being used (e.g. only data with Ground Truth annotations, or a small sample of records).
- Accept the predictions as annotations!
Appendix: Preprocess jigsaw toxicity dataset
Download the jigsaw_toxicity dataset, then downsample/format using the following script (modify the INPUT_PATH and OUTPUT_PATH to suit your needs):
import pandas as pd
import json
def gen_task(row):
labels = [
{
"from_name": field,
"to_name": "comment",
"type": "choices",
"value": {"choices": [str(int(row._asdict()[field]))]},
}
for field in [
"toxic",
"severe_toxic",
"insult",
"threat",
"obscene",
"identity_hate",
]
]
return {
"data": {"comment_text": row.comment_text},
"annotations": [
{
"result": labels,
"ground_truth": True,
"was_cancelled": False,
}
],
}
INPUT_PATH = "/Users/pakelley/Downloads/Jigsaw Toxicity Train.csv"
OUTPUT_PATH = "/Users/pakelley/Downloads/toxicity-sample-ls-format.json"
df = pd.read_csv(INPUT_PATH)
sample = df.sample(n=100)
label_studio_tasks = [gen_task(row) for row in sample.itertuples()]
with open(OUTPUT_PATH, "w") as f:
json.dump(label_studio_tasks, f)If you choose to, you could also easily change how many records to use (or use the entire dataset by removing the sample step).
Generate Synthetic Q&A Datasets
Overview
Synthetic datasets are datasets artificially generated rather than being collected from real-world observations. They encode characteristics similar to real data, but allow for scaling up data diversity or volume gaps in general purpose application, such as model training and evaluation. Synthetic datasets also work well in enhancing AI systems that have unbound human context as inputs and output, such as chatbot question and answers, test datasets for evaluation, and rich knowledge datasets for contextual retrieval. LLMs are particularly effective for generating synthetic datasets for these use cases, and allow you to enhance your AI system’s performance by creating diversity to learn from.
Example
Let’s expand on the Q&A use case above with an example demonstrating how to use Prompts to generate synthetic user prompts for a chatbot RAG system. Given a dataset of chatbot answers, we’ll generate some questions that could return each answer.
Create a new label studio project by importing chunks of text that would be meaningful answers from a chatbot.
You can use a preprocessed sample of the SQuAD dataset as an example. See the appendix for how this was generated.
Create a label config for question generation (or Ask AI to create one for you), for example:
<View>
<Header value="Context" />
<Text name="context" value="$context" />
<Header value="Answer" />
<Text name="answer" value="$answer" />
<Header value="Questions" />
<TextArea name="question1" toName="context"
placeholder="Enter question 1"
rows="2"
maxSubmissions="1" />
<TextArea name="question2" toName="context"
placeholder="Enter question 2"
rows="2"
maxSubmissions="1" />
<TextArea name="question3" toName="context"
placeholder="Enter question 3"
rows="2"
maxSubmissions="1" />
</View>Navigate to Prompts from the sidebar, and create a prompt for the project
If you have not yet set up API the keys you want to use, do that now: API keys.
Add instructions to create 3 questions:
Using the “context” below as context, come up with 3 questions (“question1”, “question2”, and “question3”) for which the appropriate answer would be the “answer” below:
Context:
—
{context}
—
Answer:
—
{answer}
—
note
Ensure you include {answer} and {context} in your instructions. Click answer/context above the instruction field to insert them.
Tip
You can also automatically generate the instructions using the Enhance Prompt action. Before you can use this action, you must at least add a variable name (e.g. {context} or {answer}) and then click Save.
Run the Prompt! View predictions to accept or correct.
You can read more about evaluation metrics and ways to assess your prompt performance.
Tip
You can change the subset of data being used (e.g. only data with Ground Truth annotations, or a small sample of records).
- Accept the predictions as annotations!
Appendix: Preprocess SQuAD Q&A dataset
This downloads the SQuAD dataset from Huggingface and formats it for use in Label Studio.
import pandas as pd
import json
OUTPUT_PATH = "/Users/pakelley/Downloads/qna-sample-ls-format.json"
N_SAMPLES = 100
splits = {'train': 'plain_text/train-00000-of-00001.parquet', 'validation': 'plain_text/validation-00000-of-00001.parquet'}
df = pd.read_parquet("hf://datasets/rajpurkar/squad/" + splits["train"])
sample = df.sample(n=N_SAMPLES)
sample['answer'] = sample['answers'].map(lambda item: item['text'][0])
label_studio_tasks = [{"context": row.context, "answer": row.answer} for row in sample.itertuples()]
with open(OUTPUT_PATH, "w") as f:
json.dump(label_studio_tasks, f)If you choose to, you could also easily change how many records to use (or use the entire dataset by removing the sample step).